Edit this page on github
Frequently asked questions on comdb2
This section defines the syntax of SQL as accepted by Comdb2. Anyone familiar with SQLite will find the syntax diagrams familiar. Comdb2 uses SQLite as the query parser and query planner. The SQL dialects in Comdb2 and SQLite are not identical however. Some things have been taken away and some have been added (stored procedures, time partitions).
Transactions
BEGIN

Begin a transaction. The impact of this changes somewhat based on the sessions transaction level
(SET TRANSACTION). See the transaction model
section for lots of details about available isolation levels. Quick summary follows.
In the default level (when no SET TRANSACTION statement has been run, and no defaults set
in the database configuration file) this statement has the effect of beginning a transaction which
will block all write operations together transactionally. Read operations will not run transactionally,
and thus will not see the results of intermediate operations within a transaction (prior to commit.)
In Read Committed level (SET TRANSACTION READ COMMITTED) this statement has the effect of beginning a
transaction that will group all read and write operations into a transaction. "Reads" will see
results of intermediate operations within a transaction. Long term read locks will not be held, and reads
are not "repeatable."
In Snapshot Isolation level (SET TRANSACTION SNAPSHOT ISOLATION) this statement has the effect of
beginning a transaction that will group all read and write operations into a transaction. Reads
will see results of intermediate operations within a transaction. Reads are repeatable in this mode
without the use of long term read locks through the use of Multi Version Concurrency Control. This level
also guarantees lack of phantoms. Before using snapshot isolation, you must add enable_snapshot_isolation
to your lrl file.
The optional AS OF DATETIME clause begins a transaction with a snapshot of the database as
it existed as of the given time. The snapshot only has the effects of transactions that committed
before that time. Using AS OF DATETIME requires the transaction being in SNAPSHOT ISOLATION
mode (set with SET TRANSACTION SNAPSHOT ISOLATION). Note that enabling SNAPSHOT ISOLATION
requires the enable_snapshot_isolation lrl tunable. Snapshots requested from before snapshot
isolation was enabled will not work. A snapshot is only available if enough transaction logs are
online to find commits before the specified time. The time provided must unquoted date in ISO 8601
format or Unix time.
NOTE: If any SQL statements inside the transaction fail, excluding COMMIT, the application
needs to run ROLLBACK before it's able to reuse the same connection for other requests. A
transaction that calls COMMIT or ROLLBACK is considered complete, regardless of any errors returned.
The next statement that runs on the same connection will be in a new transaction.
COMMIT

Commits a transaction previously started with BEGIN. The effect of this call will be to submit all
"write" operations that were part of the transaction to the db engine to be performed as a transaction. At this point
all constraints will be verified, and cascade operations will be performed if required. Any errors in deferred
statements will be returned at this point. Any transaction
where COMMIT returns an error is considered rolled back. It is an error to call COMMIT on a connection
where no transaction has been started with BEGIN.
ROLLBACK

Rolls back (aka aborts) the current transaction. Any effects of previous statements in the current transaction are undone.
Changing data
INSERT
insert
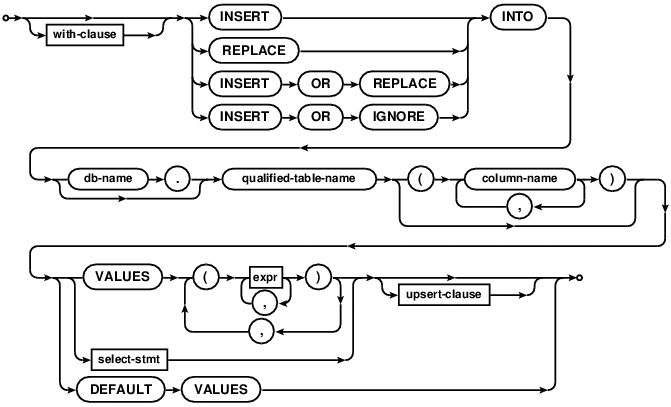
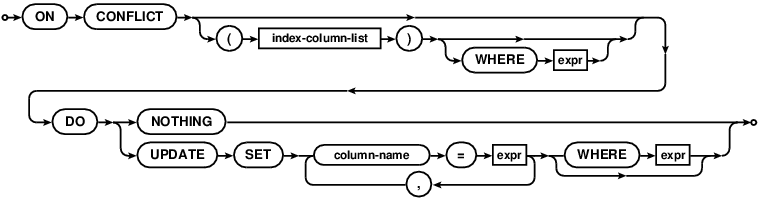
upsert-clause
The INSERT statement comes in three basic forms. The first form (with the "VALUES" keyword) creates a single new
row in an existing table. If no column-list is specified then the number of values must be the same as the number
of columns in the table. If a column-list is specified, then the number of values must match the number of
specified columns. Columns of the table that do not appear in the column list are filled with the default value (which
may be an AUTOINCREMENT for longlong fields), or with NULL if no default value is specified.
The second form of the INSERT statement takes its data from a SELECT statement. The number of columns in the
result of the SELECT must exactly match the number of columns in the table if no column list is specified, or it
must match the number of columns named in the column list. A new entry is made in the table for every row of the
SELECT result. The SELECT may be simple or compound.
The third form of the INSERT statement is with DEFAULT VALUES. This
inserts a single new row in the named table populated with default values for
columns, or with a NULL if no default value is specified as part of column
definition.
Note that if wrapped in a BEGIN/COMMIT pair, the INSERT is considered a deferred
statement, and will not return an error (except in the rare case of a connection failure) until COMMIT time.
See also:
UPDATE
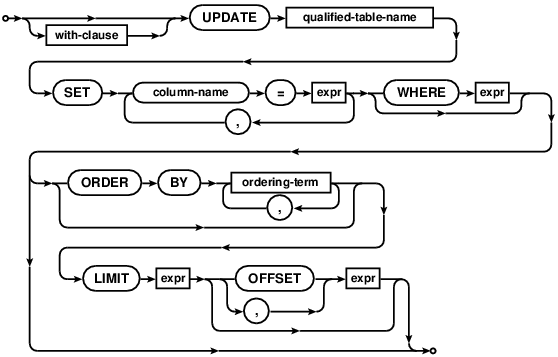
The UPDATE statement is used to change the value of columns in selected rows of a table. Each assignment in an
UPDATE specifies a column name to the left of the equals sign and an arbitrary expression to the right.
The expressions may use the values of other columns. All expressions are evaluated before any assignments are
made. A WHERE clause can be used to restrict which rows are updated.
See also:
DELETE
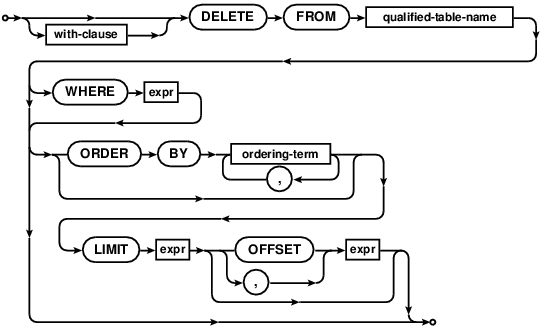
The DELETE command is used to remove records from a table. The command consists of the DELETE FROM
keywords followed by the name of the table from which records are to be removed.
If the WHERE clause is omitted, all rows will be deleted. Note that in this case, the DELETE statement
will traverse all rows and remove them individually. This makes it a less efficient option than the TRUNCATE
statement, but has the advantage that it will work on tables with foreign key constraints.
See also:
Querying data
SELECT statement
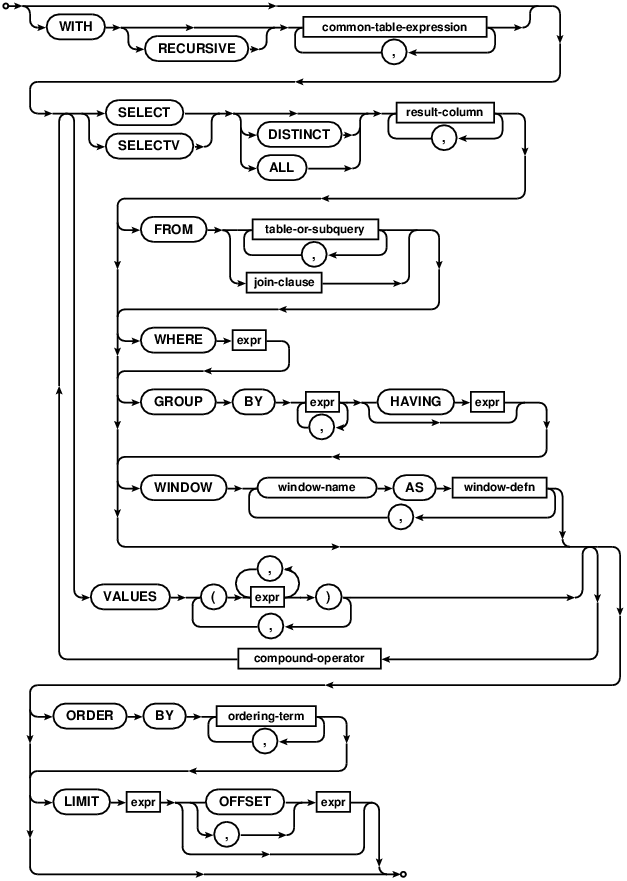
Select syntax overview
The SELECT statement is used to query the database. The result of a SELECT is zero or more rows of
data where each row has a fixed number of columns. The number of columns in the result is specified by the
expression list in between the SELECT and FROM keywords. Any arbitrary expression can be used as a
result. If a result expression is * then all columns of all tables are substituted for that one expression. If
the expression is the name of a table followed by .* then the result is all columns in that one table.
The SELECTV variant of SELECT operates exactly the same as SELECT and supports exactly the same syntax.
The difference is SELECTV causes Comdb2 to assert that the rows visited during the SELECTV remain
unchanged at the time of a COMMIT. It can be used in a similar manner to the SELECT FOR UPDATE construct
provided by other systems. Note that SELECTV can only be used in the following transactional modes: default,
READ COMMITTED and
SNAPSHOT ISOLATION. READ COMMITTED is the recommended
mode for running SELECTV; we allow SELECTV in the default mode, but there are corner cases inherent to this isolation level in which the
transactions will fail, therefore SELECTV in the default mode is not recommended. SELECTV works properly
in SNAPSHOT ISOLATION, but use READ COMMITTED unless your transactions are already running in
SNAPSHOT ISOLATION (it is slightly more expensive to run in SNAPSHOT ISOLATION than
READ COMMITTED transactions).
The DISTINCT keyword causes a subset of result rows to be returned, in which each result row is different.
NULL values are not treated as distinct from each other. The default behavior is that all result rows be
returned, which can be made explicit with the keyword ALL.
The query is executed against one or more tables specified after the FROM keyword. If multiple tables names are
separated by commas, then the query is against the cross join of the various tables. The full SQL-92 join syntax
can also be used to specify joins. A sub-query in parentheses may be substituted for any table name in the FROM
clause. The entire FROM clause may be omitted, in which case the result is a single row consisting of the values of the expression list.
The WHERE clause can be used to limit the number of rows over which the query operates.
The GROUP BY clause causes one or more rows of the result to be combined into a single row of output. This is
especially useful when the result contains aggregate functions. The expressions in the GROUP BY clause do not
have to be expressions that appear in the result. The HAVING clause is similar to WHERE except
that HAVING applies after grouping has occurred. The HAVING expression may refer to values, even
aggregate functions, that are not in the result.
The ORDER BY clause causes the output rows to be sorted. The argument to ORDER BY is a list of
expressions that are used as the key for the sort. The expressions do not have to be part of the result for
a simple SELECT, but in a compound SELECT each sort expression must exactly match one of the
result columns. Each sort expression may be optionally followed by a COLLATE keyword and the name of a
collating function used for ordering text and/or keywords ASC or DESC to specify the sort order.
Note that in the absence of an ORDER BY clause the order in which rows are returned is not defined.
Each term of an ORDER BY BY expression is processed as follows:
If the ORDER BY expression is a constant integer K then the output is ordered by the K-th column of the
result set.
If the ORDER BY expression is an identifier and one of the output columns as an alias by the same name,
then the output is ordered by the identified column.
Otherwise, the ORDER BY expression is evaluated and the output is ordered by the value of that expression.
In a compound SELECT statement, the third ORDER BY matching rule requires that the expression be
identical to one of the columns in the result set. The three rules are first applied to the left-most SELECT in
the compound. If a match is found, the search stops. Otherwise, the next SELECT to the right is tried. This
continues until a match is found. Each term of the ORDER BY clause is processed separately and may come
from different SELECT statements in the compound.
The LIMIT clause places an upper bound on the number of rows returned in the result. A negative LIMIT
indicates no upper bound. The optional OFFSET following LIMIT specifies how many rows to skip at the
beginning of the result set. In a compound query, the LIMIT clause may only appear on the final SELECT
statement. The limit is applied to the entire query not to the individual SELECT statement to which it is
attached. Note that if the OFFSET keyword is used in the LIMIT clause, then the limit is the first
number and the offset is the second number. If a comma is used instead of the OFFSET keyword, then the
offset is the first number and the limit is the second number. This seeming contradiction is intentional - it
maximizes compatibility with legacy SQL database systems.
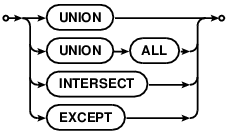
A compound SELECT is formed from two or more simple SELECT statements connected by one of the
operators UNION, UNION ALL , INTERSECT, or EXCEPT. In a compound SELECT, all the
constituent SELECT statements must specify the same number of result columns. There may be only a
single ORDER BY clause at the end of the compound SELECT. The UNION and UNION ALL
operators combine the results of the SELECT statements to the right and left into a single big table.
The difference is that in UNION all result rows are distinct where in UNION ALL there may be
duplicates. The INTERSECT operator takes the intersection of the results of the left and right SELECT
statements. EXCEPT takes the result of left SELECT after removing the results of the right SELECT.
When three or more SELECT statements are connected into a compound statement, they group from left to right.
Foreign tables
Tables specified in table-or-subquery clause may refer to tables in other databases. The
syntax is simply database.tablename. Being able to locate the database requires setting up
comdb2db. For simple setups/testing the application can
specify LOCAL_database.tablename to refer to a table in a database that's running on the same machine as
the database receiving the query. One can create an alias to a foreign table and refer to it as if
it's in a local database, see the PUT ALIAS statement. This has the advantage of being able to move
tables between databases without changing SQL statements used to query them.
See also:
Stored procedures
CREATE PROCEDURE
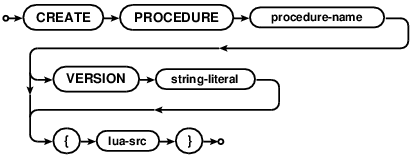
The CREATE PROCEDURE statement defines a new procedure. Procedures can be run directly with the
EXEC PROCEDURE or EXECUTE PROCEDURE statements. Defined procedures can also be registered
as new SQL functions with the
CREATE LUA FUNCTION statement, or as triggers with CREATE LUA TRIGGER/
CREATE LUA CONSUMER statements.
Procedures can be given versions. Version names are to be supplied by the user. Versioning allows a more
compartmentalized development model. For instance, users may have "beta" and "prod" versions of a procedure
to be run from different deployment stages. The SET SPVERSION statement can specify the
version to use for the current connection. The first version added for a new procedure automatically becomes a
default. Adding a new version does not make it the default - it must be made the new default version with with
the PUT DEFAULT PROCEDURE statement.
For detailed information on writing stored procedures, see the stored procedures section.
EXEC/EXECUTE PROCEDURE

Runs the stored procedure named by procedure-name. Procedures can take literal or bound parameter arguments. Stored procedure calls are immediate statements.
Creating and altering entities
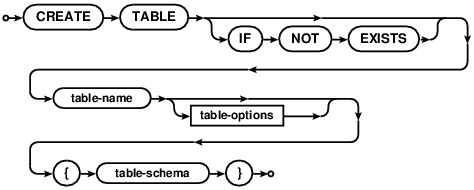
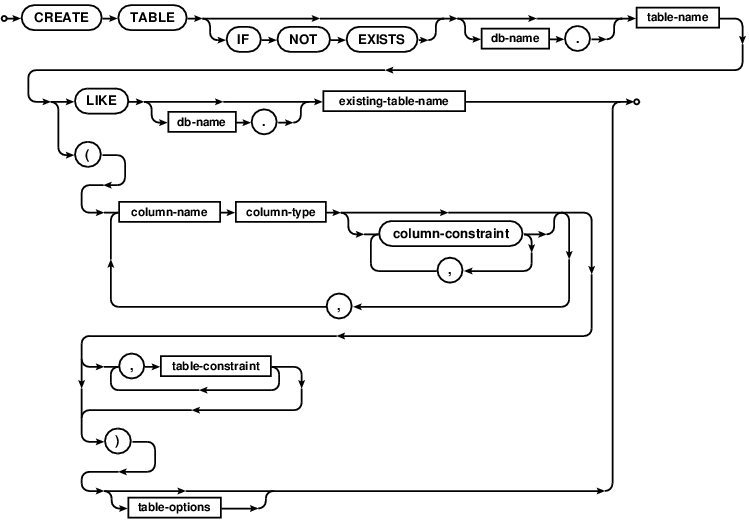
CREATE TABLE
create-table-csc2
create-table-ddl
index-column-list
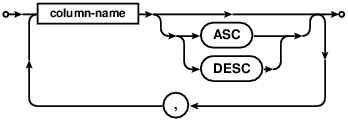
column-constraint
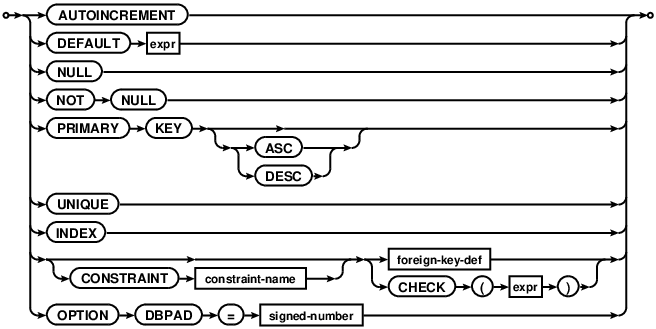
table-constraint
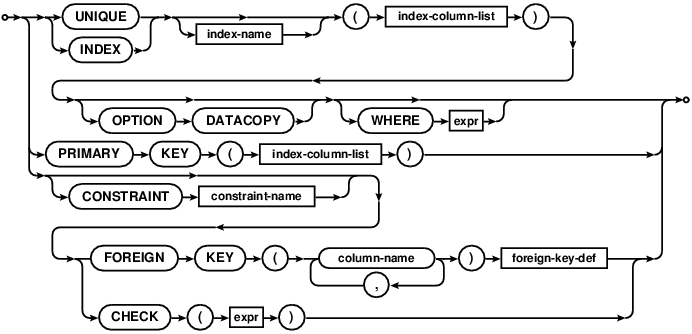
foreign-key-def
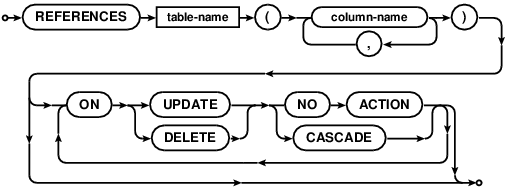
table-options
The CREATE TABLE statement creates a new table. If the table already
exists, the statement returns an error unless the IF NOT EXISTS clause
is present.
Comdb2 supports two variants of CREATE TABLE syntax. In the first approach,
the schema definition defines all keys and constraints (more information can be
found on the table schema page).
The second approach, added in version 7.0, follows the usual standard data
definition language syntax supported by other relational database systems.
A primary key created using this syntax implicitly creates a UNIQUE index
named COMDB2_PK with all key columns marked NOT NULL.
Comdb2 allows creation of indexes only on fields with fixed-sized types. For
instance, an attempt to create index on a blob or vutf8 field would result in
error. In terms of syntax, indexes on expressions need a little extra
care in Comdb2. The expression must be casted to a fixed-sized type.
CREATE TABLE t1(`json` VUTF8(128),
UNIQUE (CAST(JSON_EXTRACT(`json`, '$.a') AS INT)),
UNIQUE (CAST(JSON_EXTRACT(`json`, '$.b') AS CSTRING(10))))
The list of allowed types that the expression in an index be casted to as well as the syntax required to define an index on expression using CSC2 schema, can be found here.
See also: Schema definition language (CSC2)
CREATE LUA TRIGGER
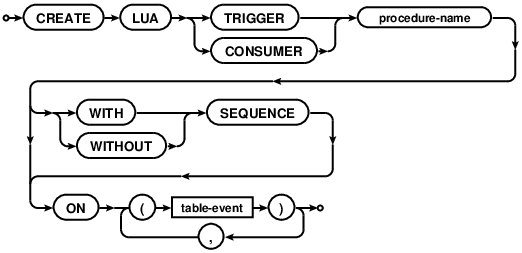
Creates a new trigger or consumer to be called for specified table events. See the Triggers section for a full explanation and examples. Briefly, triggers are run by the database when a matching table event occurs. They do not return data to the client, but may create/modify records. A common application of triggers is to create an audit table that logs record changes. Consumers register with the database the intent to listen for matching table changes. Consumers may then call the stored procedure with the given name to block and receive matching events when they occur.
Procedure-name must be a name of an existing Lua procedure created with a
CREATE PROCEDURE statement.
See also:
CREATE LUA FUNCTION

This registers a stored procedure with the list of functions known by the SQL engine. This allows the function
to be called from running SQL statements like built-in SQL functions. The SCALAR
keyword specifies that the function will return a single value given a set of arguments, eg: like the built-in
function UPPER. The AGGREGATE keyword specifies that the function will return a single value from a
subset of rows, like the built-in function SUM.
DROP
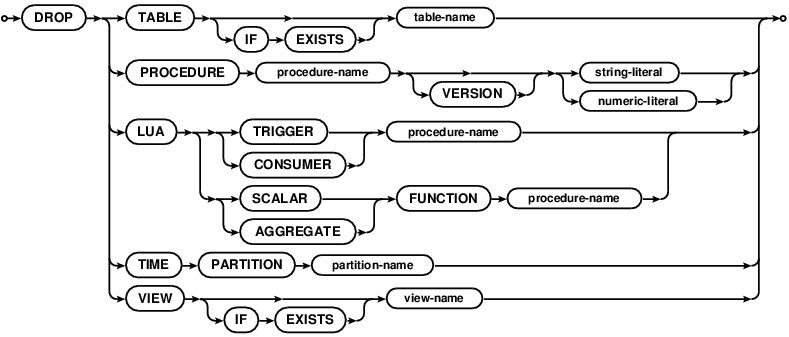
DROP will delete the specified entity from the database.
DROP TABLE will drop the specified table. If the table doesn't exist, the statement will return an error,
unless IF EXISTS is specified.
DROP PROCEDURE will drop the specified version on a procedure. See the stored procedure
section for details.
DROP LUA TRIGGER, DROP LUA CONSUMER, DROP LUA SCALAR FUNCTION and DROP LUA AGGREGATE FUNCTION
will drop the association between a stored procedure and the trigger/consumer/function that it maps to. The trigger
will no longer fire. All SQL connections running the consumer procedure will stop with an error. The named functions
will no longer be callable from SQL.
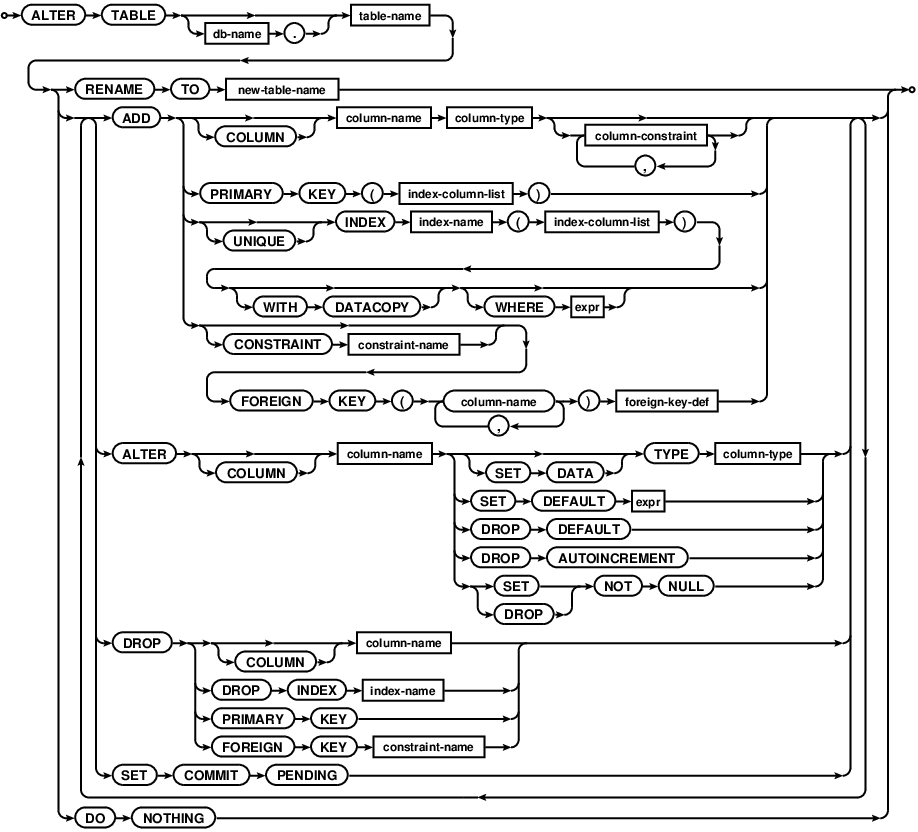
ALTER TABLE
alter-table-csc2
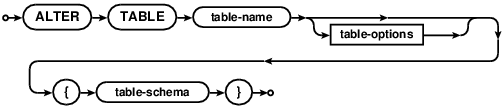
alter-table-ddl
Schema changes in Comdb2 are live by default. The database will not acquire
long duration table locks during the change and may be freely read from and
written to. If the schema change adds a new field, or grows the size of an
existing field, and doesn't modify the table keys, the change is "instant"
(unless the ISC table option is set to OFF). No table rebuild will
take place (unless the table option REBUILD is specified) if it's not
needed. If fields are removed or the size of an existing field is reduced, the
schema change will need to rebuild the existing table. If any key is modified,
it'll be rebuilt.
The ALTER TABLE statement will change the definition of the named table
to the one provided. Note that Comdb2 supports two variants of ALTER TABLE
syntax.
The first approach uses a declarative language and is not
incremental like SQL. In this approach there is no need to alter the table
multiple times to add several indices. The ALTER TABLE statement will try
to form the most efficient to change the old table definition to the new one.
Any fields present in the new schema but absent from the old will be added to
the table definition. Any fields absent in the new schema but present int the
old will be dropped. Keys will be added, renamed or changed. Constraints will
be added or removed. See the Schema definition section for
details on the table schema definition syntax. See the table options
section a list of options that may be set for a table.
The second approach, added in version 7.0, supports the usual standard data
definition language, like other relational database systems. This syntax can
be used to ADD a new column or DROP an existing column from the
table. Multiple ADD/DROP operations can be used in the same command. In case of
DROP operation, the references to the column being dropped will be
silently removed from the referring keys and constraints definitions. RENAME TO
option renames a table. This option cannot be combined with other ALTER TABLE
options.
SET COMMIT PENDING detaches the schema change from the current transaction
and schema changes that use this option will keep running until an explicit
commit/abort command is issued. Also see SCHEMACHANGE.
See also:
CREATE TIME PARTITION
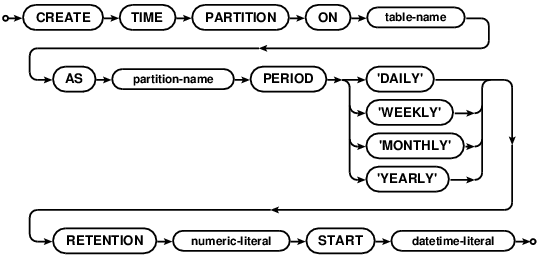
CREATE TIME PARTITION defines the data retention policy for the given table. See Time-based Table Partitioning
TRUNCATE

The TRUNCATE statement deletes all the data in a give table. It does this very efficiently by creating
a brand new table and telling the database to use it instead of the old table. For anything but very small tables
this is much more efficient than using the DELETE statement. However TRUNCATE will refuse
to operate on tables that have foreign key constraints, or are referred to by tables with foreign key constraints.
This restriction is necessary since it's not possible to quickly verify that no constraints are violated. If all
records need to be deleted from a table with/referenced by foreign key constrains, please use the DELETE
statement instead.
CREATE INDEX
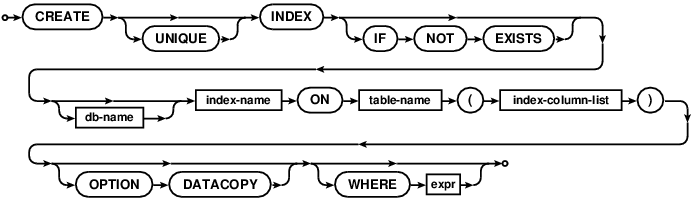
The CREATE INDEX statement can be used to create an index on an existing
table. The support for CREATE INDEX was added in version 7.0.
CREATE INDEX idx ON t1(CAST(UPPER(c) AS cstring(100)));
CREATE UNIQUE INDEX idx ON t2(CAST(i+j AS int));
DROP INDEX
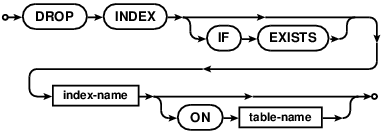
The DROP INDEX statement can be used to drop an existing index. A DROP
INDEX command without ON will drop an index with the specified name.
It, however, would fail if there are multiple indexes in the database with the
same name. The support for DROP INDEX was added in version 7.0.
CREATE VIEW

The CREATE VIEW statement can be used to create a view, which is essentially
an alias of a SELECT statement. Views cannot be used to modify records. Thus, an
attempt to INSERT, UPDATE or DELETE on a view would fail. One may think of views
as READ-ONLY tables. A list of views can be obtained by querying comdb2_views
system table.
Access control
GRANT and REVOKE


GRANT lets the named user have read or write access to the given table. REVOKE takes away that access.
Note that the access checks aren't enforced until authentication is enabled on the database as a whole with the
PUT AUTHENTICATION statement.
GRANT OP TO gives superuser privileges to a given user. That user can create/drop tables and grant/revoke
privileges to other users.
Database settings
GET
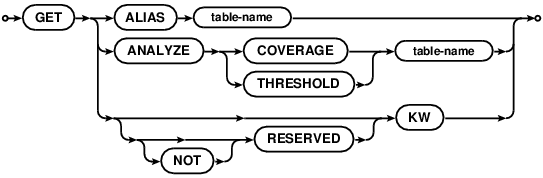
GET allows access to persistent database settings that are changed/enabled with the PUT statement. Not
all settings are gettable - passwords aren't for example, for obvious reasons. There are many other database settings
that are not exposed to the GET/PUT statement yet, but should be over time.
The settings currently available to GET are:
ALIAS- fetch the local alias name for a table in another database, see foreign tablesANALYZE COVERAGEandANALYZE THRESHOLD- fetch tunables used to configure index statistics gathering, see theANALYZEstatement.
PUT
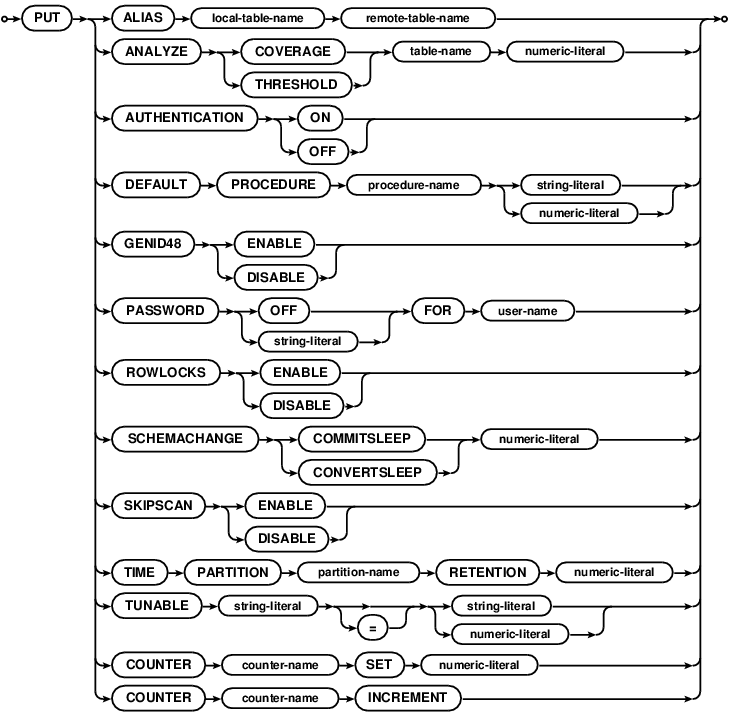
This is the counterpart to the GET statement. PUT changes persistent database settings. If authentication
is enabled with PUT AUTHENTICATION ON, only superusers can run PUT commands.
The settings currently available to PUT are:
ANALYZE COVERAGEandANALYZE THRESHOLD- set tunables used to configure index statistics gathering, see theANALYZEstatement.DEFAULT PROCEDURE- sets the default version for a given stored procedure. Calls to the stored procedure without aSET SPDEFAULTstatement will run this version. See stored procedures for and overview.ALIAS- creates local alias for a foreign tablePASSWORD- sets a password for a given user.PUT PASSWORD OFFdisables the user.AUTHENTICATION- enables/disables authentication on the database. If enabled, access checks are performed. Note that a user must be designated as a superuser before enabling authentication.TIME PARTITION- changes the time partition configuration; decreasing is possible at all times; increasing is only possible when shard numbers are in orderCOUNTER- changes the counter "counter-name" value, either incrementing it or setting it; incrementing a counter without setting it first generate a zero valued counter; a counter with the same name as a logical partition serves as the logical clock for rolling out that partition.
Operational commands
ANALYZE
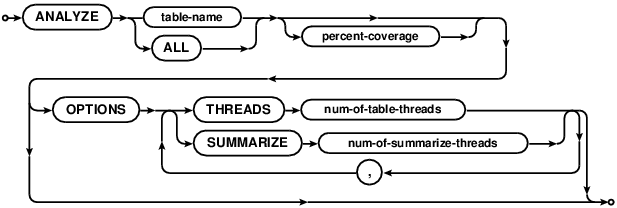
ANALYZE scans indices to gather statistics used in forming query plans. It's important that ANALYZE runs
every time there are index changes or large data changes. If the current data disagrees with statistics gathered
from the last ANALYZE run, the database may form sub-optimal (or outright poor) query plans.
ANALYZE can run on all the tables if ALL is specified, or on a single given table. The latter makes sense
when rebuilding statistics after index/data changes to a single table. Analyze runs in 2 stages
- Database scans each index and builds a "summary" - it saves a percentage of the original data to compute
statistics for.
percent-coverage(integer from 1-100) configures the percentage of data to be analyzed. The default value can be configured withPUT ANALYZE COVERAGE. - Database scans the generated summary and computes
- The selectivity of each index
- A histogram of values
Running ANALYZE on a large table is relatively expensive. There are some cost/time trade-offs that can
be set. For the most accurate data, set percent-coverage to 100 (default is 10). To speed up the process,
increase the number threads. OPTIONS THREAD configures how many tables to run in parallel (if ALL) is
specified. OPTIONS SUMMARIZE configures how many threads to use for running the first stage described above.
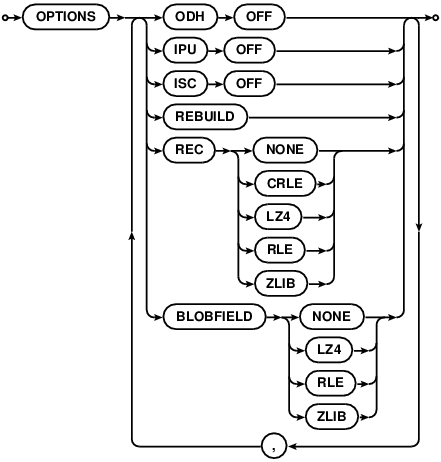
REBUILD
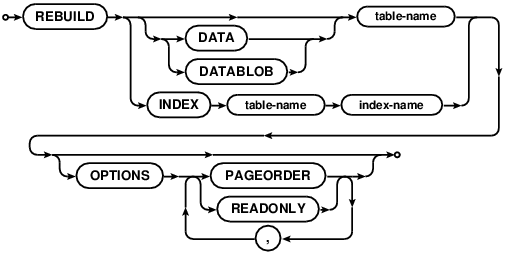
REBUILD will recreate an existing index, data, or blob, preserving old data. There are a couple of reasons run
ever run REBUILD:
- Lots of data has been deleted, and we don't anticipate adding a similar amount back. Run
REBUILDto reclaim disk space. - A table option (like compression) has been set, and we'd like to apply it to existing records immediately.
- A table/index/blob is found to be corrupt.
The READONLY and PAGEORDER options are intended for the rare cases that a table is found to be corrupt.
Setting the READONLY option will cause the cluster to drop to READONLY mode for the duration of the
rebuild. Traversing a B-Tree in PAGEORDER requires that the READONLY flag is set.
SCHEMACHANGE
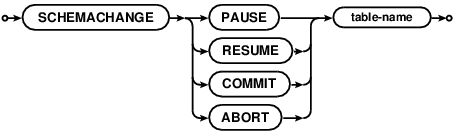
SCHEMACHANGE is an operational command to preempt ongoing schema changes:
PAUSEongoing schema changes.RESUMEalready paused schema changes. NOTE: Resumed schema changes will not commit until an explicit commit is issued.COMMITongoing schema changes. This command also resumes paused schema changes and commits after all records are converted.ABORTongoing schema changes.
Built-in functions
Most of these functions come straight from SQLite. Not all SQLite functions are available - datetime functions
are different, for example. Consult the table below for a list. New functions may be created with
CREATE LUA FUNCTION.
Available functions
Aggregate functions
In any aggregate function that takes a single argument, that argument can be preceded by the keyword DISTINCT. In such cases, duplicate elements are filtered before being passed into the aggregate function. For example, the function "count(distinct X)" will return the number of distinct values of column X instead of the total number of non-null values in column X.
REGEXP function
The REGEXP function in comdb2 is implemented as a SQLite extention. The function can be invoked either by REGEXP(A,B) or B REGEXP A, where A is the regular expression and B is the string to be matched. Note that the order of string and regular expression is flipped in both syntaxes.
The following regular expression syntax is supported:
X* zero or more occurrences of X
X+ one or more occurrences of X
X? zero or one occurrences of X
X{p,q} between p and q occurrences of X
(X) match X
X|Y X or Y
^X X occurring at the beginning of the string
X$ X occurring at the end of the string
. Match any single character
\c Character c where c is one of \{}()[]|*+?.
\c C-language escapes for c in afnrtv. ex: \t or \n
\uXXXX Where XXXX is exactly 4 hex digits, unicode value XXXX
\xXX Where XX is exactly 2 hex digits, unicode value XX
[abc] Any single character from the set abc
[^abc] Any single character not in the set abc
[a-z] Any single character in the range a-z
[^a-z] Any single character not in the range a-z
\b Word boundary
\w Word character. [A-Za-z0-9_]
\W Non-word character
\d Digit
\D Non-digit
\s Whitespace character
\S Non-whitespace character
SET statements
SET statements set an option that remains in place for the current SQL connection. They have no effect on other
existing or new connections. All SET statements are
deferred, even when not in a transaction. Any error
from specifying an option incorrectly will be returned on the next statement that runs on this connection. All
arguments to SET following the keywords is treated as a string and is not parsed further. String arguments
do not need to be quoted. For example, SET USER mike is correct. SET USER 'mike' is not correct.
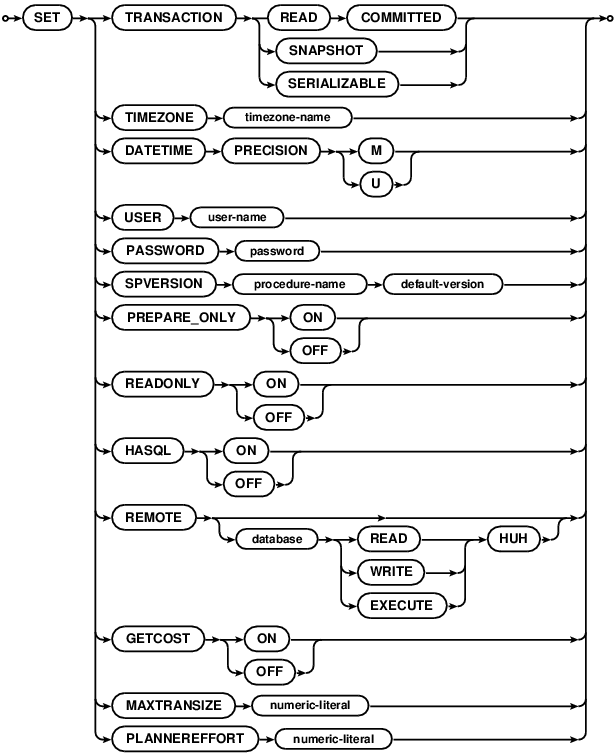
SET TRANSACTION
This sets the current connection's transaction level. See transaction levels for more details
SET TRANSACTION CHUNK
This allows bulk data processing to be automatically split into smaller size chunks, freeing the client from
the responsibility of spliting up the data. Jobs like INSERT INTO 't' SELECT * FROM 't2' are trivially handled
as a sequence of small lock-footprint transactions. Another common use-case is periodic data-set clean-up, replacing
the legacy comdb2del tool. This mode currently requires the statements to be enclosed inside a BEGIN ... COMMIT
block. Also, in this mode transactions are executed with VERIFYRETRY implicitly
disabled.
SET TIMEZONE
Sets the timezone for the current connection. All datetime values are returned in this timezone. All timezone values received from the application without an explicit timezone specified are taken to be from this timezone. Please see datetime types for more information.
SET DATETIME PRECISION
Sets the default precision of datetime times. All datetime values are returned with this precision. There are two options:
- M - sets the precision to milliseconds. Datetime values are returned with cdb2_client_datetime_t type.
- U - sets the precision to microseconds. Datetime values are returned with cdb2_client_datetimeus_t type.
SET USER
Sets the username for the current connection. Must be set if authentication is enabled (see PUT.
SET PASSWORD
Sets the password for the current connection. Must be set if authentication is enabled (see PUT.
Password check is done against the user specified by SET USER.
SET SPVERSION
Sets the version for a given stored procedure name. This overrides the default version set globally by
SET DEFAULT PROCEDURE
SET READONLY
Sets the connection in readonly mode - it will not be able to issue any statements that modify the database.
SET VERIFYRETRY
Turns transaction retries on or off. See the section on optimistic concurrency control for lots of details. The short version is that turning this ON makes the database retry transactions on conflict. Turning it OFF makes the user retry.
SET HASQL
Turns on "high availability" mode for SQL. Normally, if a connections is in a transaction, or is receiving rows
from a query, the failure of the current database node will result in an error returned to the user. If HASQL is on,
the client will keep track of the snapshot start point, of all queries run, and of the current position in the result
set for the latest query. On node failure, the snapshot will be re-established on a different node, all statements
will be replayed, and the current query will resume where it left off. This is only available in SNAPSHOT
or SERIALIZABLE transaction isolation levels.
SET REMOTE
This restricts access to foreign tables on the current connection. This is useful for tools that can control the level of access a user has to databases other than the current database.
SET GETCOST
This allows the application to call comdb2_getprevquerycost() on a connection after running a query. This function returns a text description of the paths taken by the query, and the associated cost. Useful for tooling.
SET MAXTRANSIZE
This sets the maximum number of operations a transaction will do. The default limit is 50000. Every record
added by INSERT, updated by UPDATE, or deleted by DELETE counts towards this total. Transactions
that pass the limit are rejected.
SET PLANNEREFFORT
Sets a tunable that determines how hard the query planner will work to estimate the cost of possible query plans. The setting is a number from 1 (least effort, quickly formed plans) to 10 (most effort, possibly better plans). The default setting is 1.
SET ROWBUFFER
Configures row-buffering. The default is ON, where a server writes a row into a buffer and does not flush the buffer
immediately. When off, a server flushes on every single row and hence it may reduce latency.
SET SSL_MODE
Sets client-side SSL mode. See SSL Mode Summary for details.
SET SSL_CERT_PATH
Sets SSL certificate path. See Client SSL Configuration Summary for details.
SET SSL_CERT
Sets path to the SSL certificate. See Client SSL Configuration Summary for details.
SET SSL_KEY
Sets path to the SSL key. See Client SSL Configuration Summary for details.
SET SSL_CA
Sets path to the trusted CA. See Client SSL Configuration Summary for details.
SET SSL_CRL
Sets path to the CRL. See Client SSL Configuration Summary for details.
SET SSL_MIN_TLS_VER
Sets the mininum server TLS version. See Client SSL Configuration Summary for details.
Common syntax rules
qualified-table-name

expr
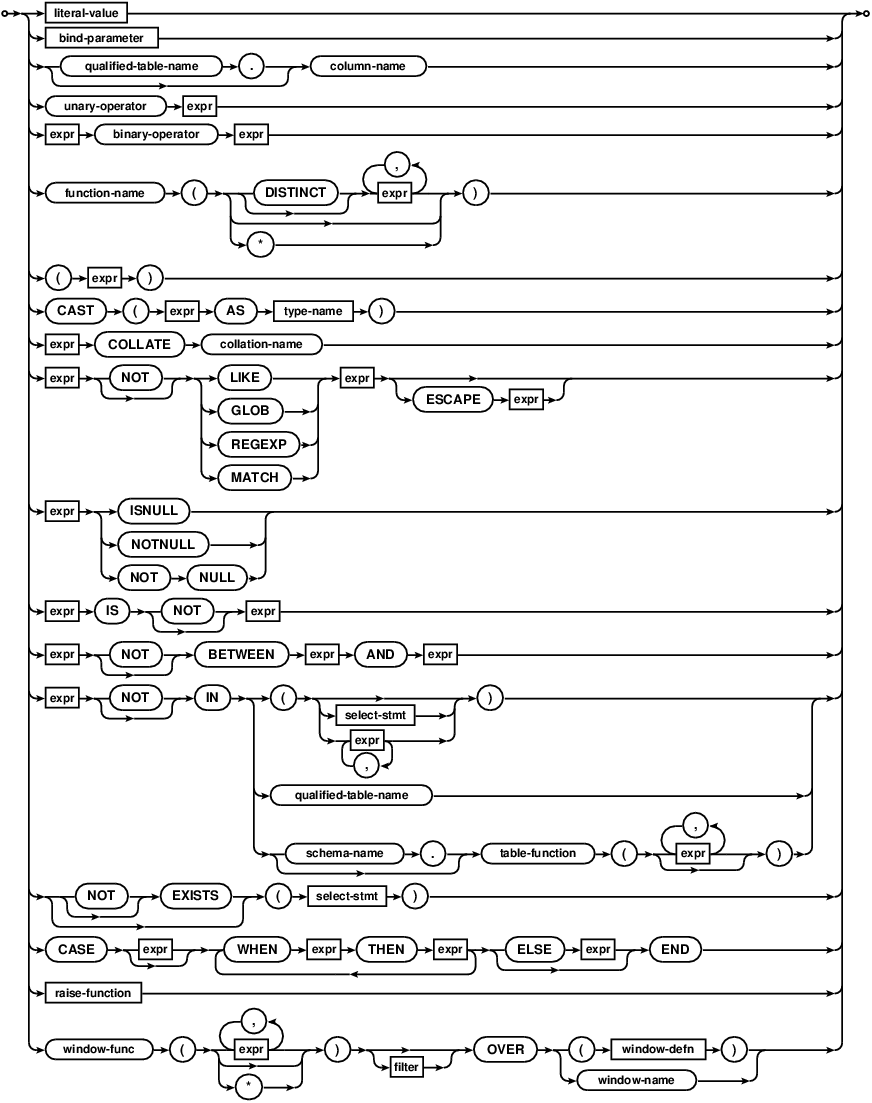
Comdb2 understands the following binary operators, in order from highest to lowest precedence:
||
* / %
+ -
<< >> & |
< <= > >=
= == != <> IN
AND
OR
Supported unary prefix operators are these:
- + ~ NOT
The COLLATE operator can be thought of as a unary postfix operator. The COLLATE operator has the highest precedence. It always binds more tightly than any prefix unary operator or any binary operator.
The unary operator + is a no-op. It can be applied to strings, numbers, or blobs and it always gives as its result the value of the operand.
Note that there are two variations of the equals and not equals operators. Equals can be either = or ==. The non-equals operator can be either != or <>. The || operator is "concatenate" - it joins together the two strings of its operands. The operator % outputs the remainder of its left operand modulo its right operand.
The result of any binary operator is a numeric value, except for the || concatenation operator which gives a string result.
A literal value is an integer number or a floating point number. Scientific notation is supported. The . character is always used as the decimal point. A string constant is formed by enclosing the string in single quotes ('). A single quote within the string can be encoded by putting two single quotes in a row. C-style escapes using the backslash character are not supported because they are not standard SQL. BLOB literals are string literals containing hexadecimal data and preceded by a single "x" or "X" character, for example X'53514C697465'
A literal value can also be the token NULL.
The LIKE operator does a pattern matching comparison. The operand to the right contains the pattern, the left hand operand contains the string to match against the pattern. A percent symbol % in the pattern matches any sequence of zero or more characters in the string. An underscore _ in the pattern matches any single character in the string. Any other character matches itself or its equivalent (i.e. case-sensitive matching). The LIKE operator is case sensitive in Comdb2.
The GLOB operator is similar to LIKE but uses the Unix file globbing syntax for its wildcards. GLOB is case sensitive. Both GLOB and LIKE may be preceded by the NOT keyword to invert the sense of the test.
A column name can be any of the names of the columns defined in the table.
SELECT statements can appear in expressions as either the right-hand operand of the IN operator, as a scalar quantity, or as the operand of an EXISTS operator. As a scalar quantity or the operand of an IN operator, the SELECT should have only a single column in its result. Compound SELECT expressions (connected with keywords like UNION or EXCEPT) are allowed. With the EXISTS operator, the columns in the result set of the SELECT are ignored and the expression returns TRUE if one or more rows exist and FALSE if the result set is empty. If no terms in the SELECT expression refer to value in the containing query, then the expression is evaluated once prior to any other processing and the result is reused as necessary. If the SELECT expression does contain variables from the outer query, then the SELECT is reevaluated every time it is needed.
When a SELECT is the right operand of the IN operator, the IN operator returns TRUE if the result of the left operand is any of the values generated by the select. The IN operator may be preceded by the NOT keyword to invert the sense of the test.
When a SELECT appears within an expression but is not the right operand of an IN operator, then the first row of the result of the SELECT becomes the value used in the expression. If the SELECT yields more than one result row, all rows after the first are ignored. If the SELECT yields no rows, then the value of the SELECT is NULL.
A CAST expression changes the datatype of the CAST. Supported values for
TEXT- convert to a string.REAL- convert to a real.INTEGER- convert to an integer.NUMERIC- convert to a real first, then convert to an integer if doing that is lossless and reversible.DATETIME- convert to a datetime.BLOB- convert to a blob.
Unknown types default to NUMERIC.
Both simple and aggregate functions are supported. A simple function can be used in any expression. Simple functions return a result immediately based on their inputs. Aggregate functions may only be used in a SELECT statement. Aggregate functions compute their result across all rows of the result set.
Common terms
common-table-expression

with-clause

result-column
table-or-subquery
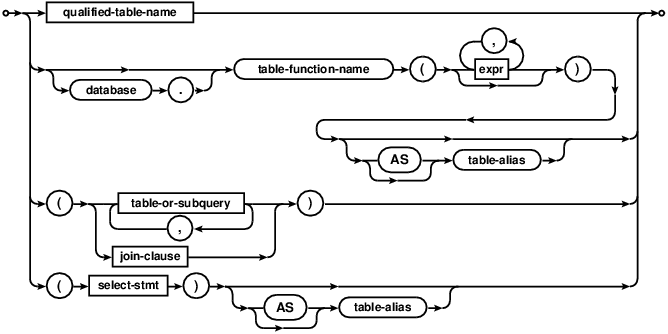
join-clause

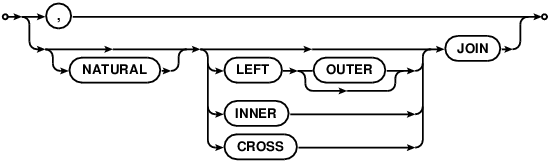
join-operator
compound-operator
ordering-term

table-event
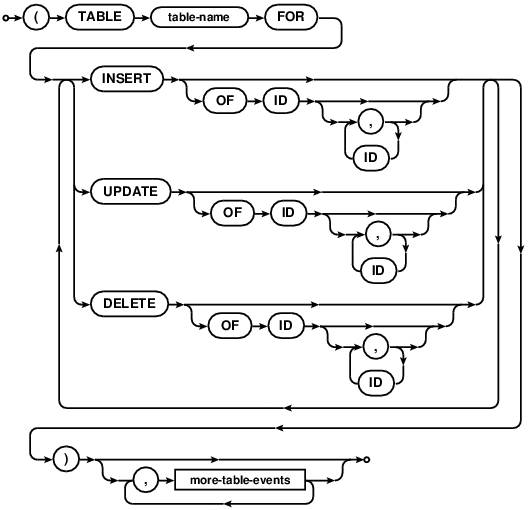
table-options
Built-in SQL functions
Note that much of this documentation comes from SQLite.
| Function | Description |
|---|---|
| ltrim (X [, Y]) | The ltrim(X,Y) function returns a string formed by removing any and all characters that appear in Y from the left side of X. If the Y argument is omitted, ltrim(X) removes spaces from the left side of X. |
| rtrim (X [, Y]) | The rtrim(X,Y) function returns a string formed by removing any and all characters that appear in Y from the right side of X. If the Y argument is omitted, rtrim(X) removes spaces from the right side of X. |
| trim (X [, Y]) | The trim(X,Y) function returns a string formed by removing any and all characters that appear in Y from both ends of X. If the Y argument is omitted, trim(X) removes spaces from both ends of X. |
| min (X [, Y, ...) | The multi-argument min() function returns the argument with the minimum value. The multi-argument min() function searches its arguments from left to right for an argument that defines a collating function and uses that collating function for all string comparisons. If none of the arguments to min() define a collating function, then the BINARY collating function is used. Note that min() is a simple function when it has 2 or more arguments but operates as an aggregate function if given only a single argument. |
| max (X [, Y, ...) | The multi-argument max() function returns the argument with the maximum value, or return NULL if any argument is NULL. The multi-argument max() function searches its arguments from left to right for an argument that defines a collating function and uses that collating function for all string comparisons. If none of the arguments to max() define a collating function, then the BINARY collating function is used. Note that max() is a simple function when it has 2 or more arguments but operates as an aggregate function if given only a single argument. |
| typeof (X) | The typeof(X) function returns a string that indicates the datatype of the expression X: "null", "integer", "real", "text", "datetime", "interval_ym", "interval_ds", "decimal", or "blob". |
| length (X) | For a string value X, the length(X) function returns the number of characters (not bytes) in X prior to the first NUL character. Since SQLite strings do not normally contain NUL characters, the length(X) function will usually return the total number of characters in the string X. For a blob value X, length(X) returns the number of bytes in the blob. If X is NULL then length(X) is NULL. If X is numeric then length(X) returns the length of a string representation of X. |
| instr (X, Y) | The instr(X,Y) function finds the first occurrence of string Y within string X and returns the number of prior characters plus 1, or 0 if Y is nowhere found within X. Or, if X and Y are both BLOBs, then instr(X,Y) returns one more than the number bytes prior to the first occurrence of Y, or 0 if Y does not occur anywhere within X. If both arguments X and Y to instr(X,Y) are non-NULL and are not BLOBs then both are interpreted as strings. If either X or Y are NULL in instr(X,Y) then the result is NULL. |
| sleep (X) | Causes the query to sleep for X seconds. Returns X. |
| printf (FORMAT, ...) | printf(FORMAT,...) The printf(FORMAT,...) SQL function works like the sqlite3_mprintf() C-language function and the printf() function from the standard C library. The first argument is a format string that specifies how to construct the output string using values taken from subsequent arguments. If the FORMAT argument is missing or NULL then the result is NULL. The %n format is silently ignored and does not consume an argument. The %p format is an alias for %X. The %z format is interchangeable with %s. If there are too few arguments in the argument list, missing arguments are assumed to have a NULL value, which is translated into 0 or 0.0 for numeric formats or an empty string for %s. |
| unicode (X) | The unicode(X) function returns the numeric unicode code point corresponding to the first character of the string X. If the argument to unicode(X) is not a string then the result is undefined. |
| char (X1,X2,...,XN) | The char(X1,X2,...,XN) function returns a string composed of characters having the unicode code point values of integers X1 through XN, respectively. |
| abs (X) | The abs(X) function returns the absolute value of the numeric argument X. Abs(X) returns NULL if X is NULL. Abs(X) returns 0.0 if X is a string or blob that cannot be converted to a numeric value. If X is the integer -9223372036854775808 then abs(X) throws an integer overflow error since there is no equivalent positive 64-bit two complement value. |
| round (X [, Y]) | The round(X,Y) function returns a floating-point value X rounded to Y digits to the right of the decimal point. If the Y argument is omitted, it is assumed to be 0. |
| upper (X) | The upper(X) function returns a copy of input string X in which all lower-case ASCII characters are converted to their upper-case equivalent. |
| lower (X) | The lower(X) function returns a copy of string X with all ASCII characters converted to lower case. The default built-in lower() function works for ASCII characters only. To do case conversions on non-ASCII characters, load the ICU extension. |
| hex (X) | The hex() function interprets its argument as a BLOB and returns a string which is the upper-case hexadecimal rendering of the content of that blob. |
| ifnull (X, Y) | The ifnull() function returns a copy of its first non-NULL argument, or NULL if both arguments are NULL. Ifnull() must have exactly 2 arguments. The ifnull() function is equivalent to coalesce() with two arguments. |
| random | The random() function returns a pseudo-random integer between -9223372036854775808 and +9223372036854775807. |
| randomblob (N) | The randomblob(N) function return an N-byte blob containing pseudo-random bytes. If N is less than 1 then a 1-byte random blob is returned. Hint: applications can generate globally unique identifiers using this function together with hex() and/or lower() like this: hex(randomblob(16)), lower(hex(randomblob(16))) |
| guid | Returns a 16-byte blob unique identifier. |
| guid_str | Returns a UUID formatted a string in the standard XXXXXXXX-YYYY-ZZZZ-AAAA-BBBBBBBBBBBB notation |
| guid | Returns a 16-byte blob unique identifier. |
| guid (X) | X should be a string representing a UUID. Returns an equivalent UUID as a blob. |
| guid_str (X) | Converts a blob X into a string UUID representation. |
| nullif (X, Y) | The nullif(X,Y) function returns its first argument if the arguments are different and NULL if the arguments are the same. The nullif(X,Y) function searches its arguments from left to right for an argument that defines a collating function and uses that collating function for all string comparisons. If neither argument to nullif() defines a collating function then the BINARY is used. |
| quote (X) | The quote(X) function returns the text of an SQL literal which is the value of its argument suitable for inclusion into an SQL statement. Strings are surrounded by single-quotes with escapes on interior quotes as needed. BLOBs are encoded as hexadecimal literals. Strings with embedded NUL characters cannot be represented as string literals in SQL and hence the returned string literal is truncated prior to the first NUL. |
| replace (X, Y, Z) | The replace(X,Y,Z) function returns a string formed by substituting string Z for every occurrence of string Y in string X. The BINARY collating sequence is used for comparisons. If Y is an empty string then return X unchanged. If Z is not initially a string, it is cast to a UTF-8 string prior to processing. |
| zeroblob (N) | The zeroblob(N) function returns a BLOB consisting of N bytes of 0x00. |
| substr (X, Y [, Z]) | The substr(X,Y,Z) function returns a substring of input string X that begins with the Y-th character and which is Z characters long. If Z is omitted then substr(X,Y) returns all characters through the end of the string X beginning with the Y-th. The left-most character of X is number 1. If Y is negative then the first character of the substring is found by counting from the right rather than the left. If Z is negative then the abs(Z) characters preceding the Y-th character are returned. If X is a string then characters indices refer to actual UTF-8 characters. If X is a BLOB then the indices refer to bytes. |
| sum(X), total(X) | The sum() and total() aggregate functions return sum of all non-NULL values in the group. If there are no non-NULL input rows then sum() returns NULL but total() returns 0.0. NULL is not normally a helpful result for the sum of no rows but the SQL standard requires it and most other SQL database engines implement sum() that way so SQLite does it in the same way in order to be compatible. The non-standard total() function is provided as a convenient way to work around this design problem in the SQL language. The result of total() is always a floating point value. The result of sum() is an integer value if all non-NULL inputs are integers. If any input to sum() is neither an integer or a NULL then sum() returns a floating point value which might be an approximation to the true sum. Sum() will throw an "integer overflow" exception if all inputs are integers or NULL and an integer overflow occurs at any point during the computation. Total() never throws an integer overflow. |
| avg(X) | The avg() function returns the average value of all non-NULL X within a group. String and BLOB values that do not look like numbers are interpreted as 0. The result of avg() is always a floating point value as long as at there is at least one non-NULL input even if all inputs are integers. The result of avg() is NULL if and only if there are no non-NULL inputs. |
| count(X), count(*) | The count(X) function returns a count of the number of times that X is not NULL in a group. The count(*) function (with no arguments) returns the total number of rows in the group. |
| group_concat(X [, Y]) | The group_concat() function returns a string which is the concatenation of all non-NULL values of X. If parameter Y is present then it is used as the separator between instances of X. A comma (",") is used as the separator if Y is omitted. The order of the concatenated elements is arbitrary. |
| glob(X, Y) | The glob(X,Y) function is equivalent to the expression "Y GLOB X". Note that the X and Y arguments are reversed in the glob() function relative to the infix GLOB operator. If the sqlite3_create_function() interface is used to override the glob(X,Y) function with an alternative implementation then the GLOB operator will invoke the alternative implementation. |
| like(X, Y [, Z]) | The like() function is used to implement the "Y LIKE X [ESCAPE Z]" expression. If the optional ESCAPE clause is present, then the like() function is invoked with three arguments. Otherwise, it is invoked with two arguments only. Note that the X and Y parameters are reversed in the like() function relative to the infix LIKE operator. The sqlite3_create_function() interface can be used to override the like() function and thereby change the operation of the LIKE operator. When overriding the like() function, it may be important to override both the two and three argument versions of the like() function. Otherwise, different code may be called to implement the LIKE operator depending on whether or not an ESCAPE clause was specified. |
| comdb2_version | Returns a string corresponding to the current version of Comdb2. |
| table_version | |
| partition_info | |
| comdb2_host | Returns the hostname on which this query is executing. |
| comdb2_dbname | Returns the name of the connected database. |
| comdb2_prevquerycost | Returns the cost of the previously executed query, when possible. |
| comdb2_user() | Returns the name of the current authenticated user for the session. |